24.06.2025
В МФТИ синтезировали антибиотик нового класса, способный справиться с резистентным золотистым стафилококком. «Стимул» бе...


После публикаций об истории искусственного интеллекта, его математических и философских основаниях мы предоставляем слово специалисту по практическому применению ИИ.
Мы встретились с профессором Центра добычи углеводородов Сколковского института науки и технологий Дмитрием Коротеевым, который занимается проблемами использования методов ИИ в нефтегазодобыче, чтобы узнать о перспективах этой работы.
— Искусственный интеллект, все эти цифровые технологии начали активно проникать в различные сферы деятельности — в промышленность, а особенно в финансы и ритейл — несколько лет назад. Сама по себе эта наука сильно не новая. Но лет пять-семь назад произошел серьезный прорыв. Сначала он был в основном связан с обработкой изображений, с распознаванием образов на изображении, когда компьютеры все лучше и лучше отличали собачек и кошечек на фотографиях. Потом эти возможности начали распространяться в те области, где собрано много-много данных. Появились рекомендательные системы в каком-нибудь «Амазоне», на который два раза в год зайдешь, а на третий раз тебе предлагают сразу то, что надо. И при этом ты даже не успел еще ничего спросить.
![]() Когда в компаниях увидели, что от применения искусственного интеллекта появляется ценность, которую можно выразить даже в деньгах, они стали все больше и больше делиться с нами, мы стали больше и больше проектов для них делать
Когда в компаниях увидели, что от применения искусственного интеллекта появляется ценность, которую можно выразить даже в деньгах, они стали все больше и больше делиться с нами, мы стали больше и больше проектов для них делать
2014—2015 годы стали «окном возможностей» и в нефтянке, где собирается очень большое количество самых разных данных, но они полноценно не используются. Отсюда и возникла идея попробовать скрестить искусственный интеллект и машинное обучение с нефтянкой, чтобы оптимизировать самые разные процессы. Я, наверное, в России один из пионеров таких решений. В 2016 году мы создали в Сколтехе группу, которую назвали Digital Petroleum Research, и начали пробовать работать с нефтяными данными так, чтобы получались алгоритмы, которые, во-первых, сами обучаются, а во-вторых, после обучения уже способны что-нибудь прогнозировать и предложить, какое-то оптимальное решение.
Хорошо, что у нас получилось заинтересовать индустриальные компании. Они с нами начали делиться данными. И мы начали работать с алгоритмами на реальных данных. Когда в компаниях увидели, что действительно от применения искусственного интеллекта появляется ценность, которую можно выразить даже в деньгах, они стали все больше и больше делиться с нами, мы стали больше и больше проектов для них делать.
— А какие компании можно выделить на этом поприще?
— Наверное, можно выделить «Газпром нефть». Сейчас к движению активно присоединяются «ЛУКойл» и «Роснефть». Из иностранных очень активными всегда на этом поле были BP и Shell. С остальными мы просто не работали, хотя у всех сейчас уже есть свои подразделения, работающие с искусственным интеллектом.
— Что в данном случае понимается под искусственным интеллектом и какие его приемы используются в первую очередь?
— Классическое определение искусственного интеллекта: это наука о создании интеллектуальных машин и программ, которые могут выполнять аналитические, а иногда и творческие функции. Это очень общее определение. Для меня в искусственном интеллекте важны три основных направления. Во-первых, это машинное обучение, представляющее собой алгоритмы, которые тренируются прогнозировать или классифицировать только на данных. Во-вторых, это гибридное моделирование, то есть машинное обучение, скрещенное с моделированием физических процессов, когда есть уравнение, описывающее какой-то процесс, а в этих уравнениях не определены основные коэффициенты. С помощью машинного обучения их можно найти. И наконец, это современные методы оптимизации. На пересечении этих трех математических «китов» стоят те алгоритмы, которые мы пытаемся разработать и тестировать.
— То есть математическая база для вас уже готова. Вы разрабатываете на ее основе алгоритмы или собственно математикой тоже приходится заниматься?
— Если говорить про нас конкретно, то мы больше все-таки не математики, а, скажем так, инженеры, которые используют существующие заготовки и доделывают, адаптируют их под конкретные процессы, чтобы собрать из них правильный алгоритм или последовательность блоков, обрабатывающих данные, чтобы решать конкретные прикладные задачи для нефтяной отрасли.
— Какие примеры вы могли бы привести?
— Их очень много разных. Мы смотрим на все аспекты жизни месторождения, начиная с ранних стадий, когда производится геологоразведка, внутри которой есть сейсмическая разведка, внутри которой есть геофизические исследования скважин, внутри которых есть гидродинамические исследования скважин, и исследования керна. Керн — это образцы горной породы, которые достаются при бурении.
На каждой из этих фаз мы стараемся что-то ускорить, что-то оптимизировать. Например, при сейсмической разведке получается огромное количество данных, из них собираются так называемые сейсмические кубы — ЗD-изображения — и их обрабатывают эксперты, выделяют в них структуры, которые являются индикатором того, где надо бурить первые скважины. Это выделение структур — длительный процесс. Он занимает в зависимости от куба от недели до года. Мы этот процесс стараемся автоматизировать с помощью обучения глубоких нейронных сетей, чтобы он занимал минуты, секунды.
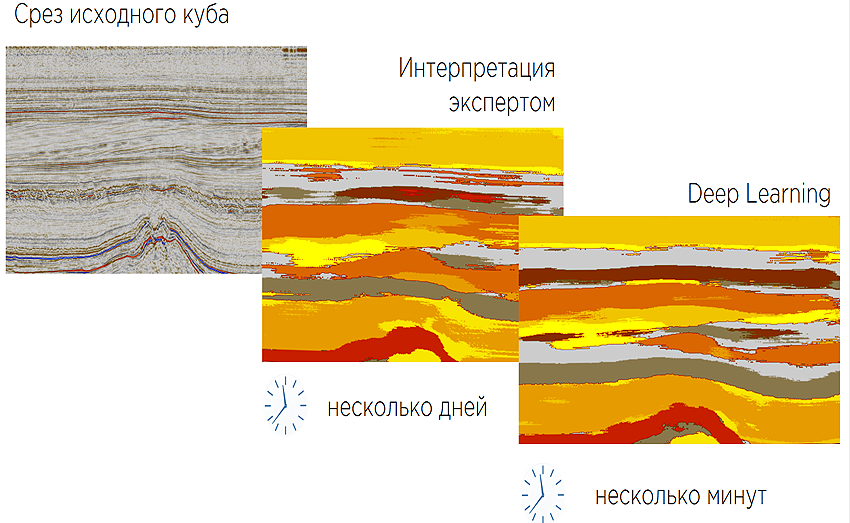
Для геофизических исследований скважин мы создаем такие инструменты, которые говорят, что эти конкретные скважины следует еще исследовать, а на соседние нефтяным компаниям можно не тратить деньги, потому что мы и так можем спрогнозировать с помощью машинного обучения, что там будет.
Исследования образцов горной породы, керна, мы тоже оптимизируем с помощью систем, очень похожих на те, что используются в рекомендательных системах, в «Амазоне», например, или в «Озоне». На основе данных, полученных на части исследованной керновой коллекции, мы можем сказать, что их достаточно для того, чтобы новые кусочки керна уже не исследовать, не тратить на это время и деньги, а потратить время на другие образцы, на которых искусственный интеллект не способен по своим математическим ограничениям дать хороший прогноз. Это первый блок — блок разведки.
Второй блок — это разработка и строительство скважин. В строительстве скважин это оптимизация бурения, потому что бурение, наверное, самый затратный процесс при освоении месторождений. В процессе бурения современных скважинах собирается огромное количество данных. Это так называемая поверхностная телеметрия, когда измеряются моменты нагрузки, скорости циркуляции бурового раствора, давления и так далее. Используются также «подземные» измерения. Это в первую очередь каротаж при бурении. На основе всех этих данных и исторических данных, накопленных при бурении прошлых скважин, мы разрабатываем такие системы, которые советуют: здесь можно ускорить процесс проходки процентов на двадцать, а здесь лучше, наоборот, не спешить, потому что если даже вы захотите ускорить, то скорее всего у вас получится авария, скважина обрушится и вы потратите кучу денег и времени на то, чтобы это ликвидировать.
![]() Мы смотрим на все аспекты жизни месторождения, начиная с ранних стадий, когда производится геологоразведка, внутри которой есть сейсмическая разведка, внутри которой есть геофизические исследования скважин, внутри которых есть гидродинамические исследования скважин, и исследования керна
Мы смотрим на все аспекты жизни месторождения, начиная с ранних стадий, когда производится геологоразведка, внутри которой есть сейсмическая разведка, внутри которой есть геофизические исследования скважин, внутри которых есть гидродинамические исследования скважин, и исследования керна
Что касается разработки, то там можно пытаться ускорить процессы моделирования течения в пласте. Сейчас они моделируются на основе физических уравнений, таких как уравнения теплопроводности или температуропроводности (закон Дарси). Они используются для того, чтобы моделировать распространение многофазных флюидов в пласте. В пласте почти всегда присутствуют и нефть, и газ, и вода. Причем сама нефть может быть сложная, многокомпонентная (часть более вязкая, часть более легкая и так далее). Для того чтобы в принципе понять, где бурить, в какие скважины закачивать воду, из каких и как откачивать, строят так называемую гидродинамическую модель пласта. Это трехмерная модель, составленная из кубиков. Каждый кубик описывается тем, сколько там, в принципе, сидит разных флюидов, как легко они подвижны. На эти все кубики накладывается уравнение температуропроводности, чтобы понять динамику происходящих в пласте процессы.
— А что значит кубики?
— Трехмерный элемент пласта представляется в виде вокселей — трехмерных пикселей. Каждый воксель со своими свойствами. Этих кубиков может быть от миллиона для среднего месторождения до миллиарда, даже парочки миллиардов.
Мы поговорили про разведку, разработку и бурение, а третья фаза — это добыча. Там вообще огромный потенциал применения всех наших технологий, для того чтобы подбирать правильные режимы работы насосов — погружных, которые из скважины откачивают жидкость, так и нагнетательных, которые с поверхности закачивают в скважину воду, чтобы вытеснять другую нефть. Там огромный потенциал для того, чтобы оптимизировать так называемые геолого-технические мероприятия на скважинах. Дело в том, что это тоже очень затратная статья для нефтяных компаний. Например, чтобы сделать гидроразрыв пласта или кислотную обработку так называемой призабойной зоны. Надо быть уверенным, что если ты делаешь определенную процедуру, то она приносит тебе те дополнительные баррели нефти, за которые ты заплатил подрядчику. Собственно, цель всех этих мероприятий — максимизировать это отношение, дополнительные баррели, деленные на затраты. Эту функцию можно максимизировать с использованием машинного обучения, тренируясь на исторических мероприятиях, на соседних скважинах. Собственно, этим мы тоже занимаемся.
![]() Надо быть уверенным, что если ты делаешь определенную процедуру, то она приносит тебе те дополнительные баррели нефти, за которые ты заплатил подрядчику. Собственно, цель всех этих мероприятий — максимизировать это отношение, дополнительные баррели, деленные на затраты
Надо быть уверенным, что если ты делаешь определенную процедуру, то она приносит тебе те дополнительные баррели нефти, за которые ты заплатил подрядчику. Собственно, цель всех этих мероприятий — максимизировать это отношение, дополнительные баррели, деленные на затраты
Есть еще одна задача для нас — оптимизация поверхностной инфраструктуры. На больших месторождениях она огромная. Там куча труб, куча сепараторов, они как-то между собой соединены, и не всегда есть даже нормальные чертежи и характеристики всех этих труб. И по информации, собираемой с разных точек этих месторождений, с использованием так называемого упрощенного моделирования, прокси-моделирования этих систем с коэффициентами, которые тоже можно формировать с помощью машинного обучения, можно стараться предлагать оптимальные решения по использованию этой поверхностной инфраструктуры. Можно еще искать почему и где может что-то пойти не так по тому, что происходит в данный момент времени в других точках инфраструктуры.
— Что значит «оптимальное использование»?
— Дело в том, что там часть сепараторов может быть перегружена, часть недогружена. Часть емкостей, в которых временно хранится нефть, может быть перегружена, часть совсем недогружена, потому что там она, например, близко к экспортной трубе с промысла. Эти вещи тоже очень важно оптимизировать.
Или бывает так, что какой-то кусок системы перестает работать: оттуда перестает поступать нефть, и никто не понимает почему. Если «натравить» натренированный на этой сети алгоритм, он может «сказать»: «Смотрите в эту и эту трубу. Скорее всего, там что-то случилось».
— А в чем состоят особенности применения ИИ в нефтегазодобыче, по сравнению с другими областями?
— Основная проблема, безусловно, в так называемых геологических неопределенностях. Если коротко, то никто на самом деле не знает, что происходит между скважинами. Конечно, эти кубики, о которых я говорил, распределяют на пространстве между скважинами, какие-то свойства им приписывают, но делают все это с помощью очень косвенных измерений и экспертной оценки того, что несут эти измерения. В основном это сейсмические измерения, которые дают на самом деле скорость распространения волн, либо это пересчитывается в упругие константы — коэффициенты Юнга, Пуассона, а нужно для модели знать еще и пористость, проницаемость и начальное насыщение разными флюидами. По сравнению со всеми остальными индустриями, наверное, самые большие неопределенности в подземной части нефтянки. Конечно, мы стараемся контролировать протекающие процессы с помощью наших моделей на искусственном интеллекте, но мы до конца не знаем, в общем-то, исходную физику этого всего. Но в этом как раз, наверное, и бонус машинного обучения, что ему необязательно знать физику. Для него главное, чтобы данные отражали правильность процесса. Тогда прогноз может не иметь какой-то суперфизической обоснованности, но все равно соотносится потом с реальностью.

— То есть соотносится с предыдущим опытом?
— Да. Еще, наверное, нефтяная отрасль одна из самых закрытых с точки зрения данных. Очень мало компаний готовы выкладывать даже обезличенные данные о своих месторождениях, профилях добычи по скважинам куда бы то ни было, и с этим тоже приходится работать. Это не всегда легко.
Дело в том, что запасы, количество углеводородов, которое стоит на учете в конкретном месторождении, это, в общем-то, один из прямых вкладов в капитализацию компании. Конечно, компании обязаны делиться всей информацией с государственными структурами. Но и там эта информация не всегда открыта, потому что это уже государственная тайна.
— А вы уже пробовали применять ваши методы на каких-то конкретных объектах?
— Да. Мы вместе с IBM сделали алгоритм для «Газпром нефти», который работает в центре сопровождения бурения.
И этот же алгоритм тестируем на реальных месторождениях «Газпром нефти». Мы начали работать с двумя другими крупнейшими российскими НК, но там я не могу пока детали раскрывать. Там мы тоже работаем с абсолютно реальными данными и с реальными производственными процессами.
Мы сильно, в двести раз, ускорили так называемое региональное петрофизическое моделирование, которое является предвестником гидродинамического моделирования с использованием правильного сбора данных и их правильной автоматической упаковки.
— Академик Константин Рудаков в интервью нашему журналу сказал, что слишком много уделяется внимания, если говорить о государственной политике в области искусственного интеллекта, технологическим, техническим приемам, а недостаточно — математическим основаниям. И что это может завести в тупик.
— Я прочел это интервью. Вы знаете, я очень прагматично смотрю на эти вещи. Как я уже сказал, мы скорее математики-инженеры, чем математики, и мы, в общем, стараемся к каждой проблеме подобрать из огромного количества фундаментально проработанных алгоритмов то, что может сработать. Причем стараемся в основном смотреть на самые последние алгоритмы, и не только российские, но и по всему миру. Чаще в последнее время у нас даже работают какие-то алгоритмы, которые публикуют ребята из Индии, Штатов, Китая. Сейчас очень много чего выбрасывается в открытый доступ, и это можно модифицировать, не нарушая, кстати, лицензионных соглашений.
![]() Мы до конца не знаем исходную физику этого всего. Но в этом как раз, наверное, и бонус машинного обучения, что ему необязательно знать физику. Ему главное, чтобы данные отражали правильность процесса
Мы до конца не знаем исходную физику этого всего. Но в этом как раз, наверное, и бонус машинного обучения, что ему необязательно знать физику. Ему главное, чтобы данные отражали правильность процесса
Я понимаю, что, наверное, фундаментальным математическим школам хочется больше государственной поддержки. С одной стороны, они правы, потому что фундаментальные исследования надо продвигать, а на суперфундаментальные исследования в индустрии очень неохотно выделяют деньги. Но с другой стороны, наверное, надо часть этих исследований пытаться «приземлить» прямо сразу на что-то прикладное, протестировать, показывать эффект и таким образом еще привлекать и негосударственное финансирование.
— Чтобы бизнес понимал, что это дает…
— Да. Я вообще смотрю в основном на прикладные проблемы и стараюсь проверить наши гипотезы о том, как тот или иной алгоритм может сработать, а отбросив то, что не работает, быстро попытаться довести предлагаемые решения до практического результата, который можно встраивать в IT-инфраструктуру компании.
— Вы говорите, что алгоритмы выкладывают в открытый доступ. А разве они не является предметом патентования?
— Сами по себе математические алгоритмы машинного обучения практически непатентабельны. Что можно патентовать? Это системы, например, принятия решений или системы оптимизации процессов, основанные на этих алгоритмах, но сама математика не патентуется.
Мы патентуем, но мы патентуем последовательность действий, то есть системы, основанные на алгоритмах. В каком-то из блоков этих последовательностей действий может сидеть машинное обучение, один из алгоритмов. В каком-то блоке может сидеть оптимизационный алгоритм и так далее. Ноу-хау в основном то, как правильно скрестить это все и собрать в последовательность. По-русски это называется либо метод, либо способ, либо система.
— Все эти разработки сделаны в Сколтехе или у вас есть какая-то компания?
— Чуть больше года назад мы с руководством Сколтеха приняли решение, что надо делать спин-офф, для того чтобы прототипы, которые мы разрабатываем в виде научно-исследовательских проектов, поэффективнее внедрять в коммерческие решения. Тогда мы договорились, что учредителями будут Сколтех и ключевые члены моей команды. И сделали компанию, которая существует с января этого года и сфокусирована на коммерческих решениях на базе того, что мы уже делаем, сделали или еще будем делать в Сколтехе.
![]() Мы скорее математики-инженеры, чем математики, и мы стараемся к каждой проблеме подобрать из огромного количества фундаментально проработанных алгоритмов то, что может сработать
Мы скорее математики-инженеры, чем математики, и мы стараемся к каждой проблеме подобрать из огромного количества фундаментально проработанных алгоритмов то, что может сработать
У нас параллельно развиваются три модели коммерциализации наших разработок. С одной стороны, мы можем делать то, что мы называем development on demand (разработка по запросу). Это когда нефтяная компания приходит с конкретной проблемой, связанной с данными, и говорит: «Ребята, у вас там скорее всего что-то есть, что нам поможет. Сделайте нам разработку, чтобы мы внедрили ее в свой технологический процесс Х». Мы это делаем. Это просто контрактные обязательства. Вторая и основная ветвь развития — разработка продуктов, которые мы будем просто продавать на рынке.
— То есть это программные продукты?
— Да. И третье — консалтинг. К нам приходят некоторые компании и, условно, говорят: «Помогите нам разработать стратегию цифровизации функции геологоразведочных работ или функции бурения». Это маленькая пока вещь. Она не совсем профильная, но полезная.
В перспективе я относительно стартапа какие-то суперстратегические планы не вынашиваю, но идеалом, конечно, будет, если какая-то нефтесервисная или нефтяная компания проявит интерес и купит нас частично или полностью через несколько лет.
Темы: Интервью